Explore web search results related to this domain and discover relevant information.
Libratus, a Poker playing Neural Network developed by Carnegie Mellon University, applies Reinforcement Learning techniques along with standard backpropagation and temporal delay techniques in order to win against Poker players across the world, including the winners of past Poker Grand Tournaments.
Libratus, a Poker playing Neural Network developed by Carnegie Mellon University, applies Reinforcement Learning techniques along with standard backpropagation and temporal delay techniques in order to win against Poker players across the world, including the winners of past Poker Grand Tournaments.However, Libratus does not use current deep learning and reinforcement learning techniques, as outlined by the AlphaGO or Deepmind papers. We wanted to explore the possible benefits of using Q-Learning to create a poker bot that automatically learns the best possible policy through self-play over a period of time.The first thing we discovered when we started hunting for datasets: There were NO datasets. We couldn't find a freely available set of poker hands being played across, for example, a Poker Tournament, or otherwise play by play records of poker games. Why? Because professional poker players pay (try saying that fast!) a lot of money to find and analyze possible moves.Which means that data on hands is extremely valuable, and therefore quite expensive. Instead, we decided to try generating our own poker hands using the Dumb AI we created. We simply had the DumbAI play against itself repeatedly, and evaluated each hand position using the PokerStove hand evaluation library.
Based on Actor-Critic reinforcement learning, this paper proposes an optimal policy learning method for multi-player poker games. The RL agents can learn from self-play from scratch without any game data or expert skills. This paper will illustrate how Actor-Critic reinforcement learning is ...
Based on Actor-Critic reinforcement learning, this paper proposes an optimal policy learning method for multi-player poker games. The RL agents can learn from self-play from scratch without any game data or expert skills. This paper will illustrate how Actor-Critic reinforcement learning is applied to multi-player poker games and the according multi-agent policy update methods.Namely, each player makes a decision based on its own Actor part (policy), which is directed by its own Critic part (policy evaluation), denoted as a multi-agent multi-policy scenario. Moreover, since all the poker players, or the RL agents, have the same functions and structures, multi-player pokers could share one set of Actor-Critic architecture for decision.In experiment 5.1, the proposed multi-player poker policy learned by multi-agent reinforcement learning (the APU and Dual-APU) performs well in the games against existing policies. Additionally, the learned policies could gain steadily against policy based on hands (Sklansky, Bill Chen), policy based on rules, and MCTS policy. Therefore, it is demonstrated that the policy learned by RL approximates the optimal policy in the statistical significance.Specifically, the multi-player poker policy learning methods based on RL aim at learning a sufficiently approximate optimal policy of multi-player poker. The optimal policy denotes the policy not being exploited by facing any opponents. On the contrary, the best policy denotes the policy profits the highest against certain opponents.
It is a pure DRL with implemented algorithms such as PG, AC and PPO. pypoks does not use any search algorithm while training or playing. No prior knowledge of poker game rules is required by the RL algorithm.
Poker with Deep Reinforcement Learning, multi processing, genetic algorithms - piteren/pypoksThis script will train a set of agents with RL self-play. The script is preconfigured with many options that will fit a system with 2x GPUs (11GB).Testbed for different RL concepts like PG, A3C, PPO, and their modifications


In July the poker-playing bot Pluribus beat top professionals in a six-player no-limit Texas Hold’Em poker game. Pluribus taught itself from scratch using a form of reinforcement learning (RL) to become the first AI program to defeat elite humans in a poker game with more than two players.
Compared to perfect information games such as Chess or Go, poker presents a number of unique challenges with its concealed cards, bluffing and other human strategies. Now a team of researchers from Texas A&M University and Canada’s Simon Fraser University have open-sourced a toolkit called “RLCard” for applying RL research to card games.A team of researchers from Texas A&M University and Canada’s Simon Fraser University have open-sourced a toolkit called “RLCard” for applying RL research to card games.In July the poker-playing bot Pluribus beat top professionals in a six-player no-limit Texas Hold’Em poker game. Pluribus taught itself…While RL has already produced a number of breakthroughs in goal-oriented tasks and has high potential, it’s not without its drawbacks. An instability in applications with multiple agents for example has slowed RL development in domains with numerous agents, large states and action spaces, and sparse rewards.
We cannot provide a description for this page right now

To solve poker with reinforcement learning (RL), I have started with building the simple basics: code of poker classes like a Deck, Table and Player. I developed interfaces and two most important methods: hand evaluation for a Deck and a game loop for a Table.
This was a motivation behind leaving the RL problem for a while and focusing only on the cards understanding as a small subproblem. Working on the cardNet network concept was a total fun. It is described in detail in my previous post. To summarize the concept of cardNet: it is a network trained in a supervised manner to encode a set of cards into a single vector representation according to the poker game rules.This information is essential while making good decisions at the poker table. While developing the cardNet, I learned a lot and observed that unfortunately “simple” is sometimes not enough to make a step forward. I realized that my first RL solution couldn’t use information about cards properly.Below are some graphs of player statistics that evolve while running the RL process. About 800K hands played by 14 neural networks. ... $won — total winnings of each NN (every NN starts every hand with 500$ despite winning or losing previous one) ... PFR — preflop raise, VPIP and PFR are two most popular statistics of a poker player, in the simplest words those inform about understanding of cards value and player position at the tableI have to say that the current RL setup is no more simple. Here are some numbers: the trainings presented at the graphs were running with 400 poker tables (1200 players) simultaneously, each table was a separate process communicating using multiprocessing queues with 14 neural networks running in separate processes on 2 GPUs.

Clubs_gym is a gym wrapper around ... anything from simple Leduc or Kuhn poker to full n-player No Limit Texas Hold’em or Pot Limit Omaha. This is a multi agent environment. Documentation is found here. Deep RTS is simplified RL environment for real-time strategy ...
Clubs_gym is a gym wrapper around the clubs python poker library. clubs is used for running arbitrary configurations of community card poker games. This includes anything from simple Leduc or Kuhn poker to full n-player No Limit Texas Hold’em or Pot Limit Omaha. This is a multi agent environment. Documentation is found here. Deep RTS is simplified RL environment for real-time strategy games.15 awesome RL environments for physics, agricultural, traffic, card game, real time game, economics, cyber security & multi agent systems.Using this environment agents can be trained to interact with the Android Env using RL and achieve tasks.FinRL is one of the first open source RL environments for finance. It can be integrated into various data sources either data feeds or user imported datasets or even simulated data.

Based on Actor-Critic reinforcement learning, this paper proposes an optimal policy learning method for multi-player poker games. The RL agents can learn from self-play from scratch without any game data or expert skills. This paper will illustrate how Actor-Critic reinforcement learning is ...
Based on Actor-Critic reinforcement learning, this paper proposes an optimal policy learning method for multi-player poker games. The RL agents can learn from self-play from scratch without any game data or expert skills. This paper will illustrate how Actor-Critic reinforcement learning is applied to multi-player poker games and the according multi-agent policy update methods.Namely, each player makes a decision based on its own Actor part (policy), which is directed by its own Critic part (policy evaluation), denoted as a multi-agent multi-policy scenario. Moreover, since all the poker players, or the RL agents, have the same functions and structures, multi-player pokers could share one set of Actor-Critic architecture for decision.In experiment 5.1, the proposed multi-player poker policy learned by multi-agent reinforcement learning (the APU and Dual-APU) performs well in the games against existing policies. Additionally, the learned policies could gain steadily against policy based on hands (Sklansky, Bill Chen), policy based on rules, and MCTS policy. Therefore, it is demonstrated that the policy learned by RL approximates the optimal policy in the statistical significance.Specifically, the multi-player poker policy learning methods based on RL aim at learning a sufficiently approximate optimal policy of multi-player poker. The optimal policy denotes the policy not being exploited by facing any opponents. On the contrary, the best policy denotes the policy profits the highest against certain opponents.

In this paper, we apply variations of Deep Q-learning (DQN) and Proximal Policy Optimization (PPO) to learn the game of heads-up no-limit Texas Hold’em.
The psychology of a successful poker player, how a player demonstrates confidence through bets and bluffs combined with imperfect information makes poker very “human”. Our group aims to create a deep reinforcement learning agent that is capable of outperforming existing poker bots to demonstrate RL’s ability to “solve” non-deterministic problems.We plan to build on the existing framework Neuron_poker1. This framework provides an OpenAI gym-style environment for training and evaluating Poker agents. It also allows easy creation and integration of new poker “players”, which we create in this project.Using this framework, we create a novel PPO and modified DQN agent that outperforms the existing agents that Neuron Poker has to offer. We also experiment with other variations of DQN, such as dueling DQN and Double DQN to enhance performance.We present a deep reinforcement learning alternative to playing poker, one that does not rely on probability tables or continuous outcome trees, purely on Reinforcement Learning.
Stay up to date on the latest artificial intelligence news from Facebook.

La estrategia ROL en poker consiste en subir la apuesta a jugadores que previamente hayan hecho call y resulta tan rentable que merece la pena detallarla
Seguro que en estos tiempos que corren has oído hablar del término “rolear”. No necesariamente ha tenido que ser en un contexto de poker, ni tampoco tienes por qué saber lo que significa. Pero para eso estamos nosotros aquí, para explicarte que el rol es un concepto que se vincula a los videojuegos.En el poker las siglas ROL se traducen en “Raise Over Limp”. Este sistema consiste en realizar una subida después de que el resto de los jugadores hayan hecho limp o call, que vienen a ser sinónimos. Si esto ocurre así, te concede un gran poder en la partida y una ventaja sobre el resto que es complicada de revertir.Pero ¿por qué se considera tan rentable este método de juego? En el poker hay generalmente dos formas de conseguir ganancias: llegar a la última calle con una combinación de cartas superior a la de tu rival u obligar al contrario a abandonar antes de ese momento.¿Es posible trasladar esto al poker? Si lo pensamos bien los jugadores pueden tratar de adoptar un papel diferente al suyo habitual en las mesas para tratar de despistar al resto de rivales. Puesto que los profesionales se estudian unos a otros para intentar anticiparse a cada movimiento, no es extraño que a menudo intenten jugar de forma atípica.
To solve poker with reinforcement learning (RL), I have started with building the simple basics: code of poker classes like a Deck, Table and Player. I developed interfaces and two most important methods: hand evaluation for a Deck and a game loop for a Table.
This was a motivation behind leaving the RL problem for a while and focusing only on the cards understanding as a small subproblem. Working on the cardNet network concept was a total fun. It is described in detail in my previous post. To summarize the concept of cardNet: it is a network trained in a supervised manner to encode a set of cards into a single vector representation according to the poker game rules.This information is essential while making good decisions at the poker table. While developing the cardNet, I learned a lot and observed that unfortunately “simple” is sometimes not enough to make a step forward. I realized that my first RL solution couldn’t use information about cards properly.Below are some graphs of player statistics that evolve while running the RL process. About 800K hands played by 14 neural networks. ... $won — total winnings of each NN (every NN starts every hand with 500$ despite winning or losing previous one) ... PFR — preflop raise, VPIP and PFR are two most popular statistics of a poker player, in the simplest words those inform about understanding of cards value and player position at the tableI have to say that the current RL setup is no more simple. Here are some numbers: the trainings presented at the graphs were running with 400 poker tables (1200 players) simultaneously, each table was a separate process communicating using multiprocessing queues with 14 neural networks running in separate processes on 2 GPUs.


The article will first outline ... of Texas Hold’em. The goal of the project is to make artificial intelligence in poker game accessible to everyone. [5] An overview of RLCard....
The article will first outline the project, then provide a running example of how to train an agent from scratch to play Leduc Hold’em poker, a simplified version of Texas Hold’em. The goal of the project is to make artificial intelligence in poker game accessible to everyone. [5] An overview of RLCard.RLCard provides various card environments, including Blackjack, Leduc Hold’em, Texas Hold’em, UNO, Dou Dizhu (Chinese poker game) and Mahjong, and several standard reinforcement learning algorithms, such as Deep Q-Learning [6], Neural Fictitious Self-Play (NFSP) [7] and Counterfactual Regret Minimization [8]. It supports easy installation and rich examples with documentations.A pair trumps a single card, e.g., a pair of Jack is larger than a Queen and a King. The goal of the game is to win as many chips as you can from the other players. More details of Leduc Hold’em can be found in Bayes’ Bluff: Opponent Modelling in Poker [9]. Now, let’s train a NFSP agent on Leduc Hold’em with RLCard!Superhuman AI for heads-up no-limit poker: Libratus beats top professionals (2018). [4]Moravčík et al. DeepStack: Expert-level artificial intelligence in heads-up no-limit poker (2017). [5] Zha et al. RLCard: A Toolkit for Reinforcement Learning in Card Games (2019).
Answer (1 of 2): I don’t think it’d be properly described as reinforcement learning but generally algorithms have been very successful at mastering poker. As far as I know the state of the art methods use Counterfactual Regret Minimization (CFR or CFR+). If you just view poker as a type ...
Answer (1 of 2): I don’t think it’d be properly described as reinforcement learning but generally algorithms have been very successful at mastering poker. As far as I know the state of the art methods use Counterfactual Regret Minimization (CFR or CFR+). If you just view poker as a type of game t...

Whilst past algorithms had performance ... of their overhead in querying neural networks. PokerRL provides an RL environment and a framework ontop of which algorithms based on Deep Learning can be built and run to solve poker games....
Your trained agent is wrapped in an EvalAgent (.../rl/base_cls/EvalAgentBase). Your EvalAgent can battle other AIs in an AgentTournament (.../game/AgentTournament) or play against humans in an InteractiveGame (.../game/InteractiveGame). All local workers (just classes) can be wrapped with ~4 lines of code to work as an independent distributed worker. Some parts of PokerRL work only for 2-player games since they don't make sense in other settings.As a baseline comparison in small games, there are (unoptimized) implementations of vanilla CFR [10], CFR+ [11] and Linear CFR [12] that can be run just like a Deep RL agent and will plot their exploitability to TensorBoard. Whilst past algorithms had performance concerns mostly related to computations on the game-tree, these sampling based approaches have most of their overhead in querying neural networks. PokerRL provides an RL environment and a framework ontop of which algorithms based on Deep Learning can be built and run to solve poker games.Framework for Multi-Agent Deep Reinforcement Learning in Poker - EricSteinberger/PokerRLA more fun way to test whether your installation was successful, is running examples/interactive_user_v_user.py to play poker against yourself and examples/run_cfrp_example.py to train a CFR+ agent in a small poker game.

I want to create a poker training AI along the lines of PokerSnowie, but better. I don't know AI very well, but I do know poker. Can anyone recommend a forum where I might be able to find a RL expert to partner with?
Wow. Did you use RL to code that? PokerSnowie would beat most recreational players, but would lose to most pros, imo. There are poker AIs that play at a superhuman level, such as Pluribus.I'm not sure how they created it, but I assume RL was a big part of it. I want to create an AI like pluribus with an interface like that of PokerSnowie, so people can play against it to become better.Just curious, what is exactly is not exactly what people call RL as RL has one of the most general definitions I know, similar to optimization. ... That is a longer conversation better done over coffee than a short reddit post. Short answer: More like Skinner and less like Pavlov. ... A community to request help with your flutter code. ... r/Poker_Theory is a thought-provoking poker forum.Hello. I want to create a poker training AI along the lines of PokerSnowie, but better. I don't know AI very well, but I do know poker. Can anyone…

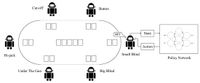
Based on Actor-Critic reinforcement learning, this paper proposes an optimal policy learning method for multi-player poker games. The RL agents can learn from self-play from scratch without any game data or expert skills. This paper will illustrate how Actor-Critic reinforcement learning is ...
Based on Actor-Critic reinforcement learning, this paper proposes an optimal policy learning method for multi-player poker games. The RL agents can learn from self-play from scratch without any game data or expert skills. This paper will illustrate how Actor-Critic reinforcement learning is applied to multi-player poker games and the according multi-agent policy update methods.Namely, each player makes a decision based on its own Actor part (policy), which is directed by its own Critic part (policy evaluation), denoted as a multi-agent multi-policy scenario. Moreover, since all the poker players, or the RL agents, have the same functions and structures, multi-player pokers could share one set of Actor-Critic architecture for decision.In experiment 5.1, the proposed multi-player poker policy learned by multi-agent reinforcement learning (the APU and Dual-APU) performs well in the games against existing policies. Additionally, the learned policies could gain steadily against policy based on hands (Sklansky, Bill Chen), policy based on rules, and MCTS policy. Therefore, it is demonstrated that the policy learned by RL approximates the optimal policy in the statistical significance.Specifically, the multi-player poker policy learning methods based on RL aim at learning a sufficiently approximate optimal policy of multi-player poker. The optimal policy denotes the policy not being exploited by facing any opponents. On the contrary, the best policy denotes the policy profits the highest against certain opponents.
In supervised learning, the poker bot is trained on a dataset of poker games. The algorithm learns patterns and strategies based on labeled data (i.e., historical outcomes of specific actions). This is useful for recognizing betting patterns and typical player behaviors. Reinforcement learning (RL) ...
In supervised learning, the poker bot is trained on a dataset of poker games. The algorithm learns patterns and strategies based on labeled data (i.e., historical outcomes of specific actions). This is useful for recognizing betting patterns and typical player behaviors. Reinforcement learning (RL) is one of the most powerful techniques for poker AI.In RL, the bot learns by playing games and receiving rewards (winning) or punishments (losing). The bot adjusts its strategy to maximize the long-term reward, similar to how human players improve over time. Deep learning with neural networks can help a poker bot process vast amounts of data and make complex decisions.Learn how to code an AI poker bot, exploring decision-making algorithms and machine learning techniques in this comprehensive tutorial for building a casino botOne of the fascinating applications of AI is creating casino bots that can play poker or other casino games autonomously. These bots leverage sophisticated algorithms and decision-making processes to compete with human players or simulate gameplay for training purposes.

Reservados todos los derechos. © RR Licores · Diseñado por Servicios Digitales
#reinforcementlearning #openspeil #pokerface #poker #gambling #gameing #python #markov #markovdecisionprocess #analysis #model #videogames #circle #pytor...
